Архитектура слоя ускорения и запросы ввода-вывода (часть 13)
При установке PernixData FVP или VMware vFlash Read Cache вы создаете слой ускорения, который (та-да-м!) ускоряет данные. Хотя это может вам показаться очевидным, он будет оказывать влияние на то, как вы будете тестировать новую среду. Давайте рассмотрим традиционную и новую архитектуры.
Традиционная архитектура с единой системой хранения
До последнего времени при разработке виртуальной инфраструктуры вам приходилось масштабировать систему хранения таким образом, чтобы сбалансировать две различные задачи: обслуживание данных и производительность ввода-вывода. Тестирование такой архитектуры было достаточно простым делом: открываем ваш любимый инструмент тестирования, выбираем симулятор нагрузки и запускаем тест. Давайте, к примеру, воспользуемся IOmeter'ом. В IOmeter вы подготавливаете диск, файл (IObw.tst) создается на постоянном уровне постоянного хранения. Это уровень - датастор, который располагается на системе хранения данных. Любая операция чтения или записи на этом файле отражает производительность, которую вы можете ожидать для реального приложения, работающего на этой системе хранения данных со сходным профилем нагрузки.
В следующем сценарии IOmeter настроен для тестирования произвольного чтения. IOmeter подготавливает диск и начинает считывать данные блоками из произвольных частей файла Iobw.tst. Виртуальная машина считывает три блока и передает блоки А, В и Б в указанном порядке. Задержка этого процесса легко вычисляется, так как вам надо просто измерить, как долго занимает выполнение одного запроса ввода-вывода, или усреднить время выполнения нескольких запросов.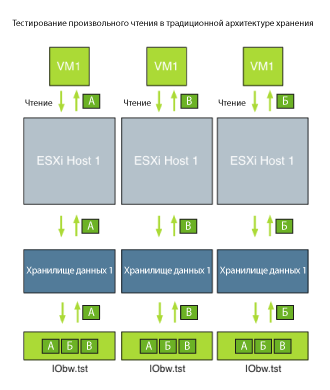
Тестирование платформы ускорения данных
Давайте посмотрим, что произойдет, если мы повторим тот же тест с использованием платформы ускорения данных.
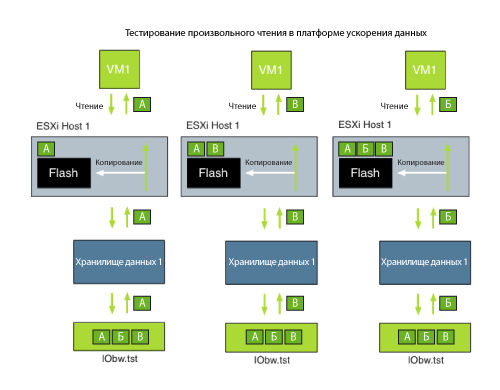 Получили ли вы преимущество от слоя ускорения? Если вы выполняли тест, в котором единократно считывали данные, то в реалии увидите снижение производительности. Не шокирующее падение, но ускорения обработки данных не будет, так как вы добавили операцию фиктивной записи в путь передачи данных. В сущности, вы не ускорили доступ к данным, добавили дополнительные операции перемещения данных без пожинания плодов преимущества от их повторного использования. Для получения дополнительной информации о фиктивных записях я рекомендую вам прочитать статью "Политики кэширования Write-Back и Write-Throuhg в FVP (FVP, часть 3)".
Получили ли вы преимущество от слоя ускорения? Если вы выполняли тест, в котором единократно считывали данные, то в реалии увидите снижение производительности. Не шокирующее падение, но ускорения обработки данных не будет, так как вы добавили операцию фиктивной записи в путь передачи данных. В сущности, вы не ускорили доступ к данным, добавили дополнительные операции перемещения данных без пожинания плодов преимущества от их повторного использования. Для получения дополнительной информации о фиктивных записях я рекомендую вам прочитать статью "Политики кэширования Write-Back и Write-Throuhg в FVP (FVP, часть 3)".
Очевидное утверждение из первого параграфа должно быть немного уточнено: "Платформа ускорения ускоряет записи (FVP) и повторяющиеся чтения". Следовательно, вам нужно изменить шаблон тестирования по умолчанию, если вы тестируете производительность чтения вашей архитектуры. Вам надо быть уверенными, что приложение читает одни и те же данные несколько раз. Это повторяет сценарии реального использования, и я знаю, что FVP оптимизирован для требований реальной жизни, а не для восхождения на пьедестал почета IOmeter.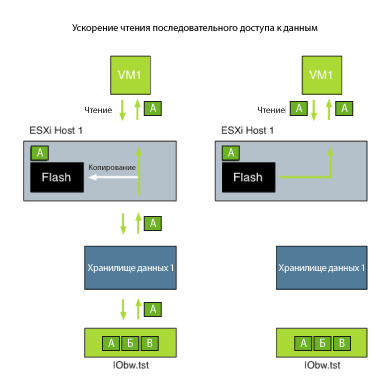
Именно поэтому мы рекомендуем использовать настоящие приложения для тестирования. Используйте приложения, которые работают в вашей инфраструктуре, переговорите с владельцами приложений и определите узкие места. Тогда при тестировании приложения на вашей платформе ускорения ввода-вывода вы сможете измерить преимущества от расположения данных ближе к приложению в пути ввода-вывода.
Однако, если вы хотите использовать IOmeter, то мы рекомендуем прогреть кэш платформы и запустить один и тот же тест два раза подряд. Это гарантирует, что большая часть данных из файла Iobw.tst будет расположена на флеш-устройстве и вы будете тестировать скорость доступа к флешу, а не всю цепочку ввода-вывода к системе хранения данных. Кроме того, выберите размер файла Iobw.tst таким образом, чтобы он считывался с дисков, а не из кэша системы хранения данных. Если вы хотите повторить реальную нагрузку, не ждите, что все данные будут находиться в кэше СХД.
С 2016 года FVP снят с продажи.